2024. 11. 27. 10:11ㆍ컴퓨터비전&AI
<회귀 모델 학습 및 비교를 통한 데이터 분석과 시각화>
import sklearn
import numpy as np
import numpy.random as rnd
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import SGDRegressor
from sklearn.preprocessing import PolynomialFeatures
# to make this notebook's output stable across runs
from sklearn.linear_model import Ridge
from sklearn.linear_model import Lasso
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
np.random.seed(42)
# To plot pretty figures
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
# Ignore useless warnings (see SciPy issue #5998)
import warnings
warnings.filterwarnings(action="ignore", message="^internal gelsd")
def plot_generated_data(X, y):
plt.plot(X, y, "b.")
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.show()
def plot_model(model_class, polynomial, alphas, **model_kargs):
for alpha, style in zip(alphas, ("b-", "g--", "r:")):
model = model_class(alpha, **model_kargs) if alpha > 0 else LinearRegression()
if polynomial:
model = Pipeline([
("poly_features", PolynomialFeatures(degree=10, include_bias=False)),
("std_scaler", StandardScaler()),
("regul_reg", model),
])
model.fit(X, y)
y_new_regul = model.predict(X_new)
lw = 2 if alpha > 0 else 1
plt.plot(X_new, y_new_regul, style, linewidth=lw, label=r"$\alpha = {}$".format(alpha))
plt.plot(X, y, "b.", linewidth=3)
plt.legend(loc="upper left", fontsize=15)
plt.xlabel("$x_1$", fontsize=18)
plt.axis([0, 3, 0, 4])
def plot_logistic(_new, y_proba):
decision_boundary = X_new[y_proba[:, 1] >= 0.5][0]
plt.figure(figsize=(8, 3))
plt.plot(X[y==0], y[y==0], "bs")
plt.plot(X[y==1], y[y==1], "g^")
plt.plot([decision_boundary, decision_boundary], [-1, 2], "k:", linewidth=2)
plt.plot(X_new, y_proba[:, 1], "g-", linewidth=2, label="Iris virginica")
plt.plot(X_new, y_proba[:, 0], "b--", linewidth=2, label="Not Iris virginica")
plt.text(decision_boundary+0.02, 0.15, "Decision boundary", fontsize=14, color="k", ha="center")
plt.arrow(decision_boundary, 0.08, -0.3, 0, head_width=0.05, head_length=0.1, fc='b', ec='b')
plt.arrow(decision_boundary, 0.92, 0.3, 0, head_width=0.05, head_length=0.1, fc='g', ec='g')
plt.xlabel("Petal width (cm)", fontsize=14)
plt.ylabel("Probability", fontsize=14)
plt.legend(loc="center left", fontsize=14)
plt.axis([0, 3, -0.02, 1.02])
plt.show()
np.random.seed(42)
m = 20
X = 3 * np.random.rand(m,1)
y = 1 + 0.5 * X + np.random.randn(m,1)/1.5
X_new = np.linspace(0,3,100).reshape(100,1)
plot_generated_data(X,y)
=> Ridge Predict value: [[1.55071465]]
SGD Predict value: [1.47012588]
<방법 2>
from sklearn.linear_model import Ridge
ridge_reg = Ridge(alpha = 1, solver = 'cholesky', random_state = 42)
ridge_reg.fit(X,y)
print('Ridge Predict value : ', ridge_reg.predict([[1.5]]))
from sklearn.linear_model import SGDClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
from sklearn.pipeline import Pipeline
sgd_reg = SGDRegressor(penalty = "l2", max_iter = 1000, tol=1e-3, random_state=42)
#sgd_reg = make_pipeline(StandardScaler(), SGDClassifier(max_iter = 1000, tol=1e-3, penalty = '12', random_state = 42))
#https://fixexception.com/scikit-learn/penalty-s-is-not-supported/
#https://runebook.dev/ko/docs/scikit_learn/modules/generated/sklearn.linear_model.sgdregressor
sgd_reg.fit(X, y.ravel())
print('SGD Predict value : ', sgd_reg.predict([[1.5]]))
<방법 1>
def plot_model(model_class, polynomial, alphas, **model_kargs):
for alpha, style in zip(alphas, ("b-","g--","r:")):
model = model_class(alpha, **model_kargs) if alpha > 0 else LinearRegression()
if polynomial:
model = Pipeline([
("poly_features", PolynomialFeatures(degree=10, include_bias=False)),
("std_scaler", StandardScaler()),
("regul_reg", model),
])
model.fit(X,y)
y_new_regul = model.predict(X_new)
lw = 2 if alpha > 0 else 1
plt.plot(X_new, y_new_regul, style, linewidth=lw, label=r"$|alpha = {}$".format(alpha))
plt.plot(X,y,"b.", linewidth=3)
plt.legend(loc="upper left", fontsize=15)
plt.xlabel("$x_1$", fontsize=18)
plt.axis([0,3,0,4])
plt.figure(figsize=(8,4))
plt.subplot(121)
plot_model(Ridge, polynomial=False, alphas=(0,10,100), random_state=42)
plt.title('Linear Regression')
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.subplot(122)
plot_model(Ridge, polynomial=True, alphas=(0,10,100), random_state=42)
plt.title('Polynomial Regression')
plt.show()

<방법 2>
plt.figure(figsize=(8,4))
plt.subplot(121)
#linear regression with Ridge
plot_model(Ridge, polynomial=False, alphas = (0, 10, 100), random_state=42)
plt.title('Linear Regression')
plt.ylabel("$y$", rotation = 0 , fontsize= 18)
plt.subplot(122)
#Polynomial regression with Ridge
plot_model(Ridge, polynomial=True, alphas=(0,10,100), random_state = 42)
plt.title('Polynomial Regression')
plt.show()
Lab2
from sklearn.linear_model import Lasso
lasso_reg = Lasso(alpha=0.1)
lasso_reg.fit(X, y)
print('Lasso Predict value:', lasso_reg.predict([[1.5]]))
=> Lasso Predict value: [1.53788174]
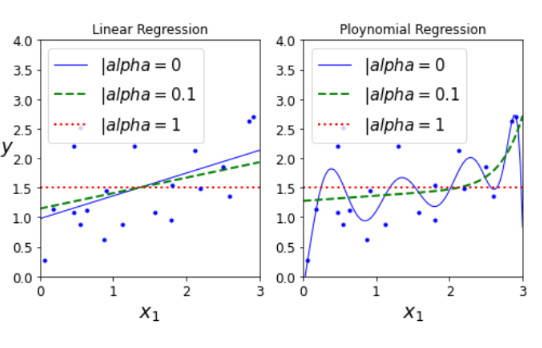
plt.figure(figsize=(8,4))
plt.subplot(121)
plot_model(Lasso, polynomial=False, alphas=(0,0.1,1), random_state=42)
plt.title('Linear Regression')
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.subplot(122)
plot_model(Lasso, polynomial=True, alphas=(0,0.1,1), random_state=42)
plt.title('Ploynomial Regression')
plt.show()
Lab 3
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
iris = load_iris()
# get familar with the iris dataset
print('Dataset kets: ', iris.keys())
# 4 features: sepal length, sepal width, petal length, petal width
print('Data sample 0: ', iris["data"][0])
# Target values
# 0: Iris-setosa, 1: Iris-versicolor, 2: Iris-Virginica
print('Target : ', iris["target"][0])
Dataset kets: dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module']) Data sample 0: [5.1 3.5 1.4 0.2] Target : 0
X = iris["data"][:, 3]
y = (iris["target"] == 2).astype(int)
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X.reshape(-1,1),y)
#print(X.reshape(-1,1))
# Create new samples for the model to predict
X_new = np.linspace(0, 3, 1000).reshape(-1, 1)
# Predict target of new samples
y_proba = log_reg.predict_proba(X_new)
plot_logistic(X_new, y_proba)
=> /usr/local/lib/python3.7/dist-packages/matplotlib/patches.py:1327: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray. verts = np.dot(coords, M) + (x + dx, y + dy)

## Question 1
Build a Logistic regression model to reconize Iris-Versicolor with following requirements
* Use 2 features >> sepal width, petal length
* Randomly split Iris data into training - test sets with ratio 8:2 using train_test_split with random_state = 10.
* Report the accuracies of model on training and test set.
**< Tip >**
model.score(data,target) 을 사용해 정확도를 구하시오.
정답 : 학습 정확도는 0.7167이고 Test 정확도는 0.7333입니다.
### 1. 데이터 로드
### 1.1) Iris 데이터 로드
iris = load_iris()
#type(iris["data"][0])
### 1.2) x와 y값 설정.
X = iris["data"][:, 1:3]
y = (iris["target"] == 1).astype(int) # versicolor
### 1.3) Train과 Test 데이터 구별
* train_test_split(feature, target, test_size, random_state)를 사용해서 학습과 테스트 데이터셋을 구별합니다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.2, random_state= 10)
#print(X_train)
### 2. 모델 빌드
### 2.1) LogisticRegression모델 빌드
from sklearn.linear_model import LogisticRegression
### 2.2) LogisticRegression 훈련
log_reg=LogisticRegression()
#print(X_train.reshape(-1, 2)) # max = 6.9
log_reg.fit(X_train.reshape(-1, 2) , y_train)
train_pred = log_reg.predict(X_train)
test_pred = log_reg.predict(X_test)
#print(test_pred)
### 3. 성능 평가
### 3.1) 학습 데이터로 스코어 평가(정확도)
* 학습 정확도는 0.7167이다.
from sklearn.model_selection import cross_val_score, cross_val_predict
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
#sgd_clf = SGDClassifier(max_iter = 1000, tol = 1e-3, random_state =42)
#cross_val_score(sgd_clf, X_train, y_train, cv= 3, scoring="accuracy")
accuracy_score(y_train, train_pred)
### 3.2) 테스트 데이터로 스코어 평가(정확도)
* Test 정확도는 0.7333이다.
accuracy_score(y_test, test_pred)
=> 0.7333333333333333
## Question 2
Build a Logistic regression model to reconize Iris-Versicolor with following requirements
* Use all 4 features
* Randomly split Iris data into training - test sets with ratio 8:2 using train_test_split with random_state = 10.
* Report the accuracies of model on training and test set.
**< Tip >**
model.score(data,target) 을 사용해 정확도를 구하시오.
정답 : 학습 정확도는 0.7083이고 Test 정확도는 0.7667입니다.
iris = load_iris()
X2 = iris["data"][:, 0:4]
y2 = (iris["target"] == 1).astype(int)
X_train, X_test, y_train, y_test = train_test_split(X2, y2, test_size= 0.2, random_state= 10)
log_reg=LogisticRegression()
#print(X_train.reshape(-1, 2)) # max = 6.9
log_reg.fit(X_train.reshape(-1, 4) , y_train)
train_pred = log_reg.predict(X_train)
test_pred = log_reg.predict(X_test)
print('학습정확도 :' , accuracy_score(y_train, train_pred) , ', 테스트 정확도 : ', accuracy_score(y_test, test_pred))
=>학습정확도 : 0.7083333333333334 , 테스트 정확도 : 0.7666666666666667
### Question **3**
from sklearn.datasets import fetch_openml
# 1) Load MNIST data
mnist = fetch_openml('mnist_784', version = 1, as_frame = False)
mnist.keys()
=> dict_keys(['data', 'target', 'frame', 'categories', 'feature_names', 'target_names', 'DESCR', 'details', 'url'])
X, y = mnist["data"], mnist["target"]
print(X.shape)
print(y.shape)
some_digit= X[0]
some_digit_image = some_digit.reshape(28, 28)
# reshape(행, 열) 데이터의 구조를 변환 https://supermemi.tistory.com/12
plt.imshow(some_digit_image, cmap=mpl.cm.binary)
# imshow https://pyvisuall.tistory.com/78 (행렬에 원하는 사이즈의 픽셀을 원하는 색으로 채움)
# https://matplotlib.org/tutorials/colors/colormaps.html
plt.axis("off") #https://kongdols-room.tistory.com/83
plt.show()
print('Label of this digit is : ', y[0])
y = y.astype(np.uint8)
(70000, 784) (70000,)
Label of this digit is : 5
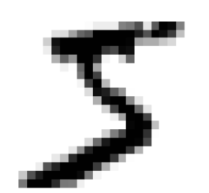
y_even = (y % 2 == 0 )
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y_even[:60000], y_even[60000:]
X_train = X_train / 255
X_test = X_test / 255
from sklearn.linear_model import SGDClassifier
sgd_mnist = SGDClassifier(max_iter = 1000, tol =1e-3, random_state = 42)
log_mnist = LogisticRegression()
sgd_mnist.fit(X_train, y_train) #데이터 학슴
log_mnist.fit(X_train, y_train)
mnist_test_pred = log_mnist.predict(X_test) # 테스트 모델 결과 테스트
accuracy_score(y_test, mnist_test_pred)
=>0.9009
mnist_test_pred = log_mnist.predict(X_test) # 테스트 모델 결과 테스트
accuracy_score(y_test, mnist_test_pred)
=>0.9009
'컴퓨터비전&AI' 카테고리의 다른 글
| [AI배울랑교] 컴퓨터 비전 (2) | 2024.11.27 |
|---|---|
| [배울랑교 AI] 컴퓨터 비전 기능을 구현 (0) | 2024.11.27 |
| [AI 과제] 농구 선수 데이터셋 학습을 통해 포지션을 예측하는 모델, 크롤링 (3) | 2024.11.27 |
| [AI 배울랑교] 2. 초연결 (2) | 2024.11.27 |
| [배울랑교 1주차] 인공지능 (0) | 2024.11.27 |