2025. 3. 4. 18:07ㆍ컴퓨터비전&AI
1️⃣ 기존 문제 (DUSt3R & MASt3R의 한계)
- ✅ 카메라 캘리브레이션이나 포즈 추정 없이 재구성하는 방식은 이미 DUSt3R, MASt3R에서 했음.
- ✅ 그런데 한 번에 딱 두 개의 뷰(pair)만 처리하는 구조라, 뷰가 많아지면 문제가 심각해짐.
- 뷰가 많아질수록 쌍(pair) 조합 수가 기하급수적으로 증가.
- 뷰 쌍끼리 정렬할 때 생긴 오류들이 누적됨.
- 그래서 나중에 Global Optimization (GO)라는 비싼 정합 과정이 필요.
- 근데 이 GO가 에러를 완벽하게 잡아내지 못함.
(뷰 쌍끼리 붙이는 거라, 전체적으로 일관된 정렬 유지가 어려움)
2️⃣ 이 논문에서 제안하는 해결책
- ✅ MV-DUSt3R:
- 한 번에 여러 뷰를 동시에 처리할 수 있는 Single-Stage Feed-Forward 네트워크.
- 핵심은 Multi-View Decoder Blocks.
- 이 블록들이 여러 뷰 정보를 한 번에 교환하면서 포인트맵을 예측.
- 한 개의 참조 뷰(reference view)를 중심으로 모든 뷰 간 정보를 조율.
- ✅ MV-DUSt3R+:
- 참조 뷰 선택이 품질에 영향을 크게 미치는 문제를 해결하기 위해,
- Cross-Reference-View Blocks 추가.
- 다양한 참조 뷰를 선택하고, 서로의 정보를 융합해서 일관성 있는 포인트맵 생성.
- 이 덕분에 특정 참조 뷰에 의존하는 문제를 완화.
- ✅ Gaussian Splatting 추가:
- 포인트맵만 만드는 게 아니라, 각 포인트마다 3D Gaussian 정보(위치, 크기, 회전, 색상, 투명도)까지 예측.
- 이렇게 예측한 Gaussian으로 바로 Novel View Synthesis (새로운 시점 이미지 합성)까지 가능하게 만듦.
- 즉, 재구성 + NVS까지 한 번에 처리하는 구조.
3️⃣ 실험
- ✅ 실험은 3가지 Task로 검증
- Multi-view Stereo Reconstruction (다중 뷰 3D 재구성)
- Multi-view Pose Estimation (다중 뷰 포즈 추정)
- 포즈 없이 재구성하는 만큼, 뷰 정렬 정확성도 중요한 평가 포인트.
- Novel View Synthesis (새로운 시점 합성)
- Gaussian Splatting 성능까지 체크.
- ✅ 결과
- 기존 DUSt3R, MASt3R보다 정확성 & 속도 모두 대폭 개선
- 특히 Global Optimization 없이 더 높은 정합 품질 달성
- Gaussian Splatting 추가로, 고품질 Novel View Synthesis까지 지원
📌 포인트
구분핵심 내용
| 기존 방식 문제 | 2개 뷰씩 처리 → 뷰 많아지면 GO 필요 → 에러 누적 |
| MV-DUSt3R | 여러 뷰 동시 처리, Multi-View Decoder, 참조 뷰 1개 |
| MV-DUSt3R+ | 참조 뷰 여러 개 선택 & Cross-Reference Fusion |
| 추가 요소 | Gaussian Splatting Head로 3D Gaussian까지 예측 |
| 주요 실험 | 3D 재구성 + 포즈 추정 + Novel View Synthesis |

💡 쉽게 말하면
- 사진 12장만 보고
- 방이 대충 어떻게 생겼는지 3D로 복원하고 (왼쪽 위)
- 그걸 가지고 "다른 각도에서는 이렇게 보일 거다" 하고 예측해서 (왼쪽 아래)
➡️ 없는 각도에서 본 화면까지 뚝딱 만들어내는 거야!
구분왼쪽 (Single Room)오른쪽 (Multi-Room)
| 공간 크기 | 작은 방 1개 | 여러 방이 있는 큰 집 |
| 뷰 수 | 12장 | 20장 |
| 처리 시간 | 0.89초 | 1.54초 |
| 의도 | 작은 공간도 포즈 없이 빠르고 정확하게 재구성 가능 | 큰 공간도 한 번에 포즈 없이 빠르게 재구성 가능 |
| 비교 대상 | 기존 DUSt3R보다 빠르고 정확함 | 기존 DUSt3R는 큰 공간에서 망가짐 (GO 문제) |
📌 기존 DUSt3R와 차이점
구분DUSt3R / MV-DUSt3R
| 뷰 처리 방식 | 2개 뷰 (쌍 처리) | N개 뷰 동시 처리 |
| 처리 방식 | 쌍마다 독립 처리 | 한 번에 N개 뷰 관계 다 고려 |
| 정렬 방식 | 나중에 Global Optimization 필요 | GO 없이 바로 정렬된 상태로 출력 |
3 Method
1️⃣ 입력 (Input)
- 사진 N장을 입력으로 받음.
I1,I2,...,InI₁, I₂, ..., Iₙ - 각 사진 크기는
H×W×3(RGB이미지)H × W × 3 (RGB 이미지) - 이때 카메라 위치(포즈) 정보, 카메라 캘리브레이션 정보 없음.
2️⃣ 참조 뷰 선택 (Reference View Selection)
- N장 중에서 1장을 **참조 뷰 (Reference View)**로 선택.
- 선택된 참조 뷰의 좌표계 기준으로, 나머지 모든 뷰의 3D 포인트맵을 예측할 거야.
➡️ 포인트맵 예측 결과는 전부 참조 뷰 좌표계로 정렬되는 구조!
3️⃣ 포인트맵 예측 (3D Pointmap Prediction)
- 각 뷰마다
H×WH × W 크기의 3D 포인트맵을 예측. - 포인트맵 =
각 픽셀이 어떤 3D 위치에 해당하는지 나타내는 좌표 (X, Y, Z). - 중요한 점:
각 뷰의 포인트맵이 전부 참조 뷰 좌표계 기준으로 정렬되어 나옴.
4️⃣ 네트워크 구조 설명 (Figure 3 설명)

- Enc (Encoder):
각 뷰를 이미지 특징맵(feature map)으로 변환. - Dec (Decoder):
각 뷰의 특징맵끼리 서로 정보 교환하면서,
최종적으로 각 뷰의 포인트맵을 예측. - 참조 뷰는 파란색 (Blue),
나머지 뷰들은 초록색 (Green)으로 표시. - 검은 실선: 각 뷰의 특징이 다음 레이어로 넘어가는 기본 흐름.
- 회색 실선: 서로 다른 뷰끼리 정보 교환하는 흐름.
➡️ 이게 바로 Multi-View Decoder Block에서 뷰 간 정보 교환하는 구조야!
5️⃣ MV-DUSt3R+ 업그레이드 포인트 (Multi-Reference)
- 원래 MV-DUSt3R는 참조 뷰 1개만 쓰는데, MV-DUSt3R+에서는 여러 뷰를 참조 뷰로 설정하고,
각 참조 뷰에서 나온 포인트맵들을 합쳐서 더 정밀하게 만든다.
6️⃣ Gaussian Splatting Head 추가 (Novel View Synthesis 지원)
- 각 뷰의 포인트맵뿐만 아니라, 포인트마다 Gaussian 파라미터(위치, 크기, 색상, 회전, 투명도)를 함께 예측.
- 이 Gaussian들을 모아 놓으면, 새로운 시점에서 보이는 장면(Novel View)을 바로 합성할 수 있음.
➡️ 포인트맵 + Gaussian 파라미터 동시 예측 덕분에
재구성 + NVS가 동시에 가능한 구조로 진화한 거야.
< 3D Gaussian Splatting , Gaussian Splatting Head 차이점>
기존 3D Gaussian Splatting은 미리 아는 포인트 클라우드 기반 후처리 방식
Gaussian Splatting Head는 포인트 위치+Gaussian을 한 번에 예측하는 End-to-End 방식
즉 위치, 크기, 회전, 색상, 투명도는 같아도 Gaussian Splatting Head는 네트워크 바로 예측한다, ( End-to-End )
📌 2️⃣ 구조 설명
✔️ Encoder (인코더)
- 각 이미지를 ViT 기반 인코더로 특징맵(Feature Map)으로 바꿈.
- 이 특징맵은 각 뷰별 토큰(visual tokens(픽셀뭉터기))이 됨.
- 특징맵 해상도는 입력 이미지보다 16배 더 작게 만듦 (해상도 줄여서 토큰 수 절감).
✔️ Decoder (디코더)
- 각 뷰의 특징맵(토큰들)을 서로 주고받으면서 정보 융합 (Multi-View Fusion).
- 뷰 간 정보 교환 = 뷰 사이 3D 정렬 맞추기 위한 과정.
- Decoder는 두 종류:
- 참조 뷰 전용 디코더 (DecBlock_ref)
- 나머지 뷰 전용 디코더 (DecBlock_src)
- 두 디코더 구조는 똑같고, 참조 뷰인지 아닌지에 따라 파라미터만 다르게 학습.
✔️ Self-Attention & Cross-Attention
- 각 뷰의 토큰들은 자기 뷰 내에서 Self-Attention으로 자기 정보 강화.
- 동시에, 다른 뷰 토큰과 Cross-Attention으로 정보 주고받음.
- 즉, "이 픽셀이 다른 뷰에서는 어디쯤일까?" 하는 걸 계속 맞춰가는 과정.
=> 이거하면 더 느려지는거 아닌가? => 토큰수 이미 줄여놓음 & 겹치는 영역이 있는 토큰들 위주로만 교환하도록 최적화 .결론. 다른데서 시간을 벌어놔서 괜찮음.
✔️ 특징맵 업데이트
- 이런 Attention + MLP 조합이 여러 층 쌓여서,최종적으로 각 뷰의 토큰들이 3D 위치 정보를 담게 됨.
- => 과거 정보를 따로 저장하거나 다시 꺼내는 과정이 따로 있는 게 아니라, 매 단계마다 업데이트된 결과를 바로바로 다음 단계에 써먹는 구조
- 여기까지가 Multi-View Decoder Block의 역할.
<최종정리>
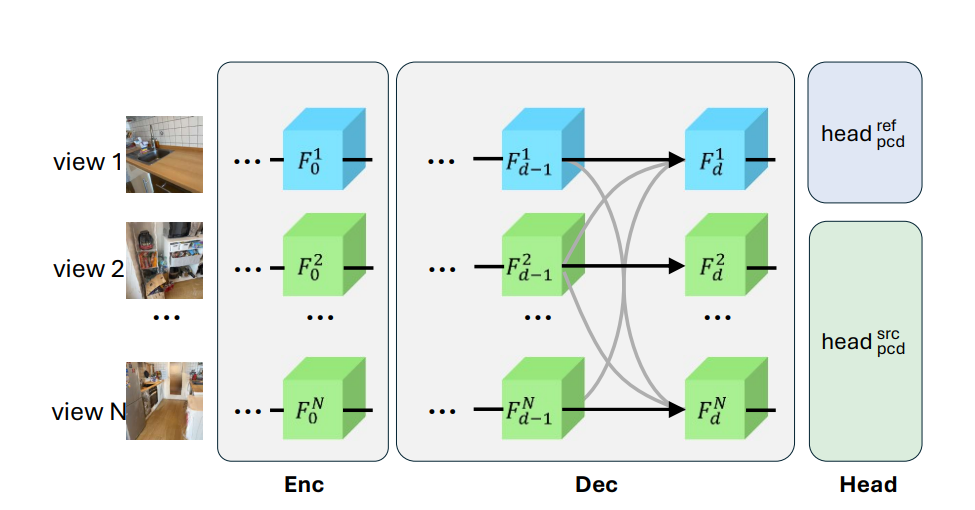
n개의 view사진을 보고 인코딩 단계에서 특징맵으로 변환한 다음 디코더 단계에서 하나의 참조뷰를 기반으로 서로 정보교환하면서 Self-Attention & Cross-Attention한다음 Head 단계에서 최종 업데이트된 토큰들을 보고, 각 뷰의 각 픽셀에 해당하는 3D 포인트맵을 예측. 다시 원래 해상도로 복원하면서, 픽셀당 3D 좌표(XYZ)와 신뢰도(confidence)를 뽑아냄
'컴퓨터비전&AI' 카테고리의 다른 글
| [논문 리뷰] VFusion3D: Learning Scalable 3D Generative Models from Video Diffusion Models (0) | 2025.07.04 |
|---|---|
| [논문정리] 3. DUSt3R: Geometric 3D Vision Made Easy (0) | 2025.02.27 |
| [논문정리] 1. DUSt3R: Geometric 3D Vision Made Easy (0) | 2025.02.23 |
| 논문 읽는 법 with 챗GPT (0) | 2025.02.12 |
| [논문리뷰였던것] Deep learning-guided video compression for machine vision tasks 였지만 VVC 이론. (0) | 2025.02.12 |