2025. 7. 2. 18:32ㆍPRO
ECCV 2024
1. Abstract & Introduction
기존 문제점 :
1. 객체 단위 인식 불가
semantic / instance-level 분할 기능이 결여
2. 3D 라벨 데이터 부족
3D 장면에서 객체 단위 학습을 위해서는 GT 라벨링 데이터가 필요
→ 수집과 라벨링에 시간·비용적 요구, 일반화 어려움
3. NeRF 기반 편집의 한계 (Implicit)
NeRF는 MLP 기반, 부분 편집을 위해 전체 네트워크 수정이 필요, 객체 단위 조작이나 분할이 어려움
가우시안을 사용하면 해결책:
1. 객체 단위 인식 가능
각 3D Gaussian에 Identity Encoding을 부여하여
→ 같은 객체에 속한 Gaussian끼리 그룹핑 가능
2. 3D 라벨 없이 학습
SAM(Segment Anything Model)이 생성한 2D
마스크 이용.
→ 3D 라벨 없이도 객체 단위 학습 가능
3. 각 객체 그룹은 독립적으로 조작 가능(Explicit)
Gaussian 기반 표현은 NeRF와 달리 부분 편집이 용이
→ 삭제, 인페인팅, 색 변경, 위치 이동 등 실시간 편집 지원

Instance-level 분할: 객체(의자1, 의자2)
Stuff-level 분할: 배경이나 재질(바닥, 벽, 하늘)
2. Related Works
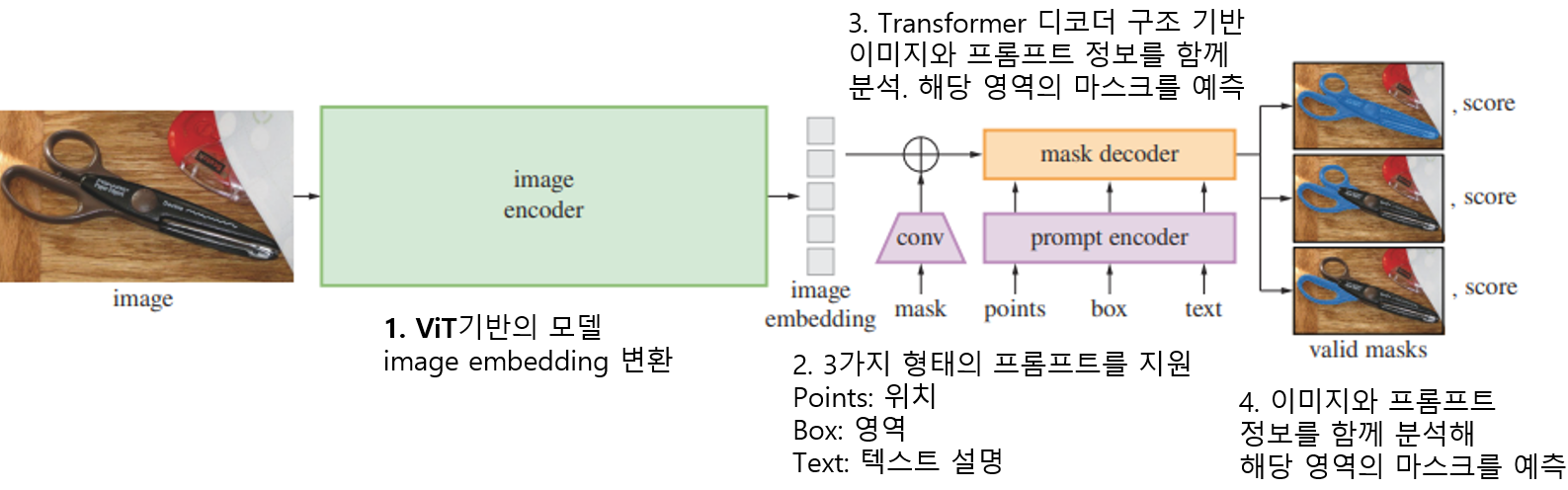
1️⃣ SAM (Segment Anything Model)
라벨 없이도 2D 이미지에서 객체를 자동으로
분할하는 AI 모델
🔍 작동 원리
1. Image Encoder
→ 이미지를 보고 시각적 특징(embedding)을 추출함
2. Prompt (점, 박스, 텍스트)
→ 사용자가 원하는 영역을 지정
3. Mask Decoder
→ 지정된 프롬프트에 따라 분할된 객체 마스크를
실시간으로 출력
📌 이 논문에서 SAM의 역할
3D 장면에는 라벨이 부족하거나 없음
SAM을 사용해 2D 이미지에서 객체 마스크를 얻고 마스크 정보를 바탕으로 3D Gaussian가 어떤 객체에 속하는지를 학습
→ 즉, 3D 라벨 없이도 객체 단위로 그룹핑 가능
2️⃣ 3D Gaussian Splatting
멀티뷰 이미지를 이용해 실제 3D 공간처럼 장면을 재구성하고 렌더링하는 기술
📌 이 논문에서 3DGS의 역할
3DGS는 외형 표현에 집중 → semantic 정보 없음
1️⃣멀티뷰 이미지 입력 → 3D Gaussian 생성
2️⃣각 Gaussian에 Identity Encoding(객체 ID 벡터) 추가
→ 비슷한 ID 벡터 = 같은 객체 소속
3️⃣SAM을 활용해 각 뷰의 2D 마스크를 얻고 이를 통해 Gaussian들의 ID를 학습
4️⃣추가로 3D 공간에서 가까운 점들끼리 비슷한 ID를 갖도록 정규화
5️⃣Gaussian들은 객체 단위로 그룹핑
3️⃣ Instance-level / Stuff-level
Instance-level (객체 중심 분할)
예: 의자1, 의자2, 노란 오리 인형 등
Stuff-level (배경 중심 분할)
→ 명확한 경계 없이도 한 그룹으로 묶음
3. Method
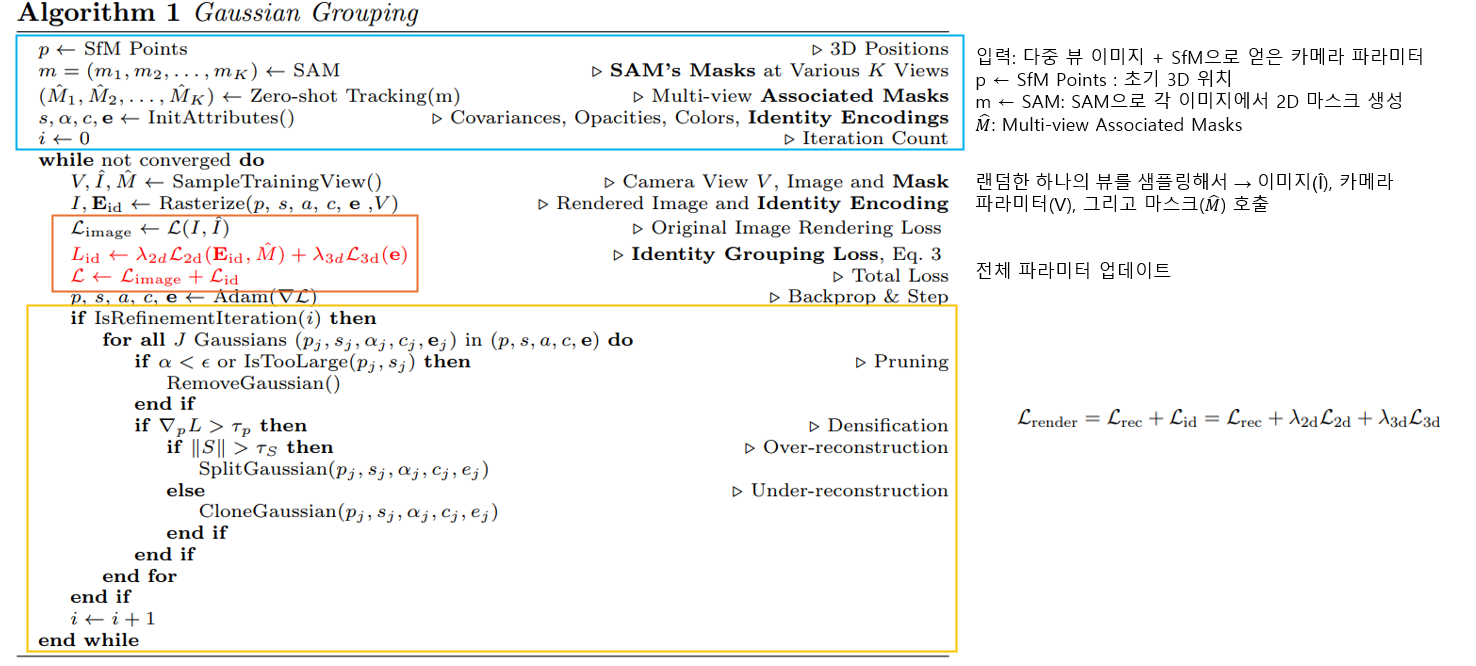
Gaussian의 기존 속성들(위치, 색상, 불투명도, 크기 등)은 그대로 유지하면서 Identity Encoding이라는 새로운 파라미터를 추가.
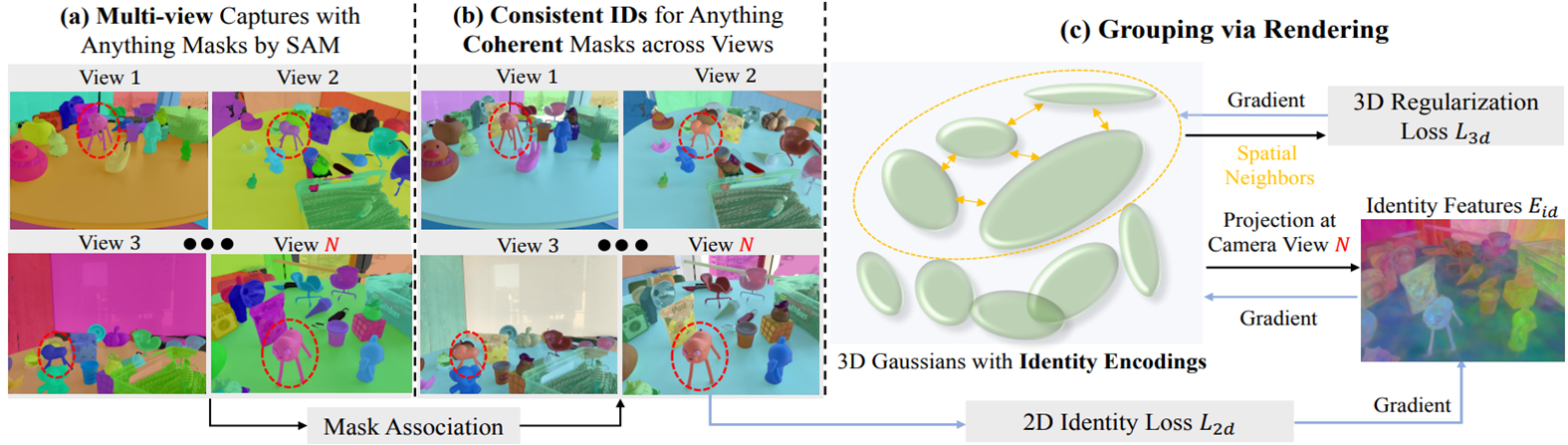
(a) SAM으로 2D에서 분할SAM을 이용해서 각 시점마다 객체 마스크를 자동으로 생성
이때는 아직 시점마다 서로 다른 ID로 분할. 즉, View 1의 파란 인형과 View 3의 파란 인형이 같은 물체라는 걸 모름
(b) 마스크가 일관되도록 정렬
UTP(universal temporal propagation model)을 사용 시간적/시점 간 마스크 추적(tracking) + 정합(alignment) 기술
Identity Encoding (객체 ID 벡터) 를 추가
2D Identity Loss (L₂d):
3D Regularization Loss (L₃d):
🔁 이 과정을 통해 3D Gaussian들이 객체 단위로 그룹핑됩니다.
3. Method: Algorithm Gaussian Grouping
4 Experiments
📌 즉: 3D에서 ID가 부드럽게 이어지는 것을 더 중요하게 봄
4 Experiments: 3DGS

SAM + DEVA 조합은 의자(chair)를 프레임 간에 제대로 분할하거나 연관시키는 데 실패
3D Gaussian 표현이 모든 뷰에서 공유되며 재구성되기 때문에,Gaussian Grouping은 잘못된 마스크 라벨을 자동으로 보정

Identity Encoding을 학습에 추가하더라도, Gaussian Splatting의 원래 목적이었던 고품질 3D 렌더링 성능에는 영향을 주지 않음


K 값에 따른 객체 제거 성능을 수치. 그림 같은 실험의 시각적 결과를 통해 K가 높을수록
더 정확하게 객체를 제거 (Loss3), 3DGS보다 성능저하 -> (객체 제거 정확도)
4. Experiments: Removal
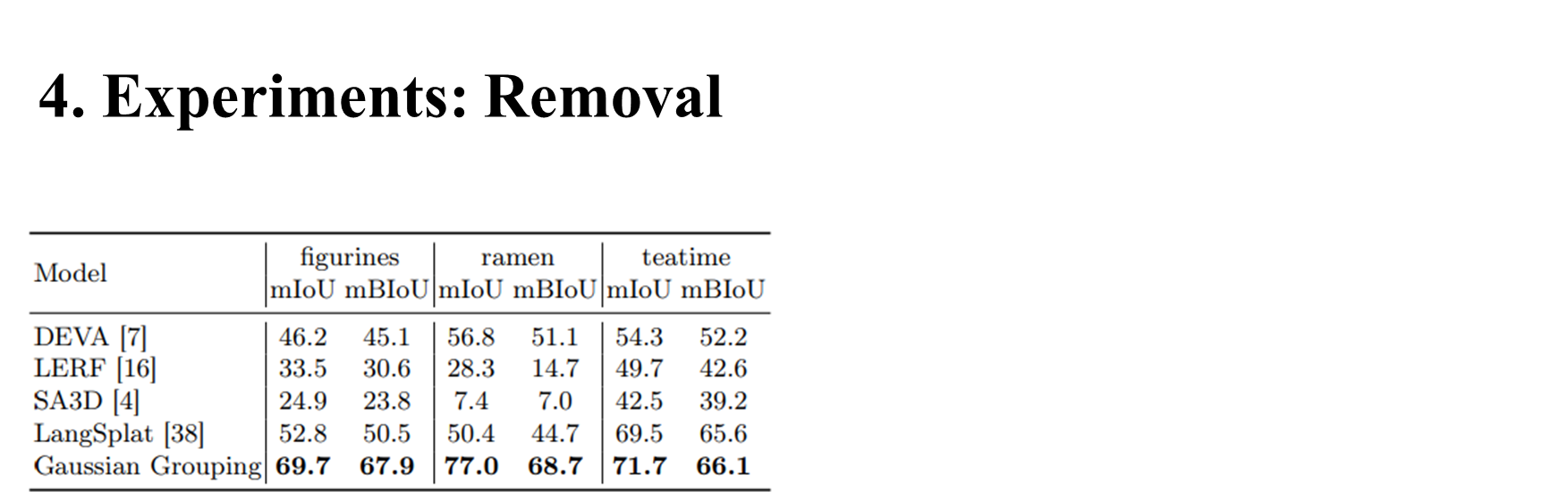
mIoU: mean Intersection over Union (객체 영역이 얼마나 정확히 맞았는가)
mBIoU: mean Boundary IoU (경계가 얼마나 정확히 맞았는가)
| 3D 분할 모델 | 성능 특성 |
| DEVA | 고전적인 2D segmentation 추론 기반. 성능은 중간 수준 |
| LERF | 텍스트 쿼리 기반 localization. 하지만 정확한 마스크 분할은 부족 (낮은 mBIoU) |
| SA3D | 3D 어텐션 방식이지만 성능 낮음 |
| LangSplat | Gaussian 기반 3D 방법. 성능이 꽤 높음 |
| Gaussian Grouping | 모든 장면에서 가장 높은 mIoU / mBIoU 기록 → 최고 성능 |
4. Experiments: 3D Object Inpainting

1시간의 학습, 20분의 파인튜닝만으로 작업을 완료
SPIn-NERF는 전체 다시 학습 -> 시간 많이 듦.
4. Experiments: 3D Object Style Transfer

| InstructNeRF2NeRF | Gaussian Grouping |
| 느림 (전체 NeRF 재학습 필요) | 빠름 (일부 Gaussian만 수정) |
| 약간 왜곡됨 | 곰 형태 그대로 유지 |
| 색상은 반영되지만 경계 불분명 | 더 자연스럽고 세밀한 스타일 적용 |
| 전체 씬 재학습 필요 | 국소 Gaussian만 수정 → 효율적 |
5. Limitation
제안된 3D Gaussian Grouping은 동적 장면이나 시간 변화에 따른 업데이트를 지원하지 않기 때문에,
현재는 정적인 3D 장면에만 적용이 가능합니다
논문 장점
: 3DGS을 사용하는 목적이 확실 (Edit시 속도 측면)
논문 단점
: Removal에 초점 맞춰진 실험인 것 같다. (Table 여부, 설명 페이지 수)