2025. 7. 1. 18:56ㆍPRO
DUSt3R이후 또 이상한 괴물같은게 나옴(Positive) CVPR best 논문이라든데 말이 안됨.
(+dust3r뜰 줄 알았다.)
dust3r : https://hyeone.tistory.com/41?category=686023

초록(Abstract)
VGGT, a feed-forward neural network이다.g camera parameters, point maps, depth maps, and 3D point
tracks 이미지를 1초 이내에 reconstructing.
=> DUSt3R은 2장끼리는 feed-forward neural network 이후 여러장 할 때는 후처리 필요.
1. Introduction
전통적으로 3D 재구성은 번들 조정(Bundle Adjustment, BA)과 같은 반복 최적화 기법을 활용하는 시각 기하학(visual-geometry) 방식으로 접근. 복잡성과 계산 비용이 크게 증가.
=> 기하학 후처리를 배제.
VGGT는 카메라 파라미터, 깊이 맵, 포인트 맵, 3D 포인트 트랙 등 장면의 모든 핵심 3D 속성을 예측.
=> Single Forward Pass로 몇 초 만에 수행
3D 재구성을 위해 특별히 설계된 네트워크를 만들 필요조차 없다. 표준적인 대규모 트랜스포머에 기반.
2. Related Work
2.1 Structure from Motion(SfM): COLMAP으로 image matching, triangulation, bundle adjustment 단계
https://xoft.tistory.com/88 여기 잘 정리 돼 있으니 여길 보시오
2.2 Multi-view Stereo(MVS): 여러 겹치는 이미지로부터 장면의 기하학을 고밀도로 재구성하는 것을 목표
MV-DUST3R+, Fast3R 등은 테스트 타임 최적화를 신경망으로 대체하는 방식을 탐구했지만 성능이 최적화되지 못하거나 비슷한 수준.
2.3 point tracking : VGGT의 feature가 기존 점 추적기와 결합될 때 SOTA 달성
3. 방법(Method)
VGGT는 다수의 이미지를 입력으로 받아, 다양한 3D 정보를 출력하는 대규모 트랜스포머 모델
3.1절에서 문제 정의, 3.2절에서 아키텍처를 설명, prediction
heads in Sec. 3.3, 3.4절에서 학습 설정
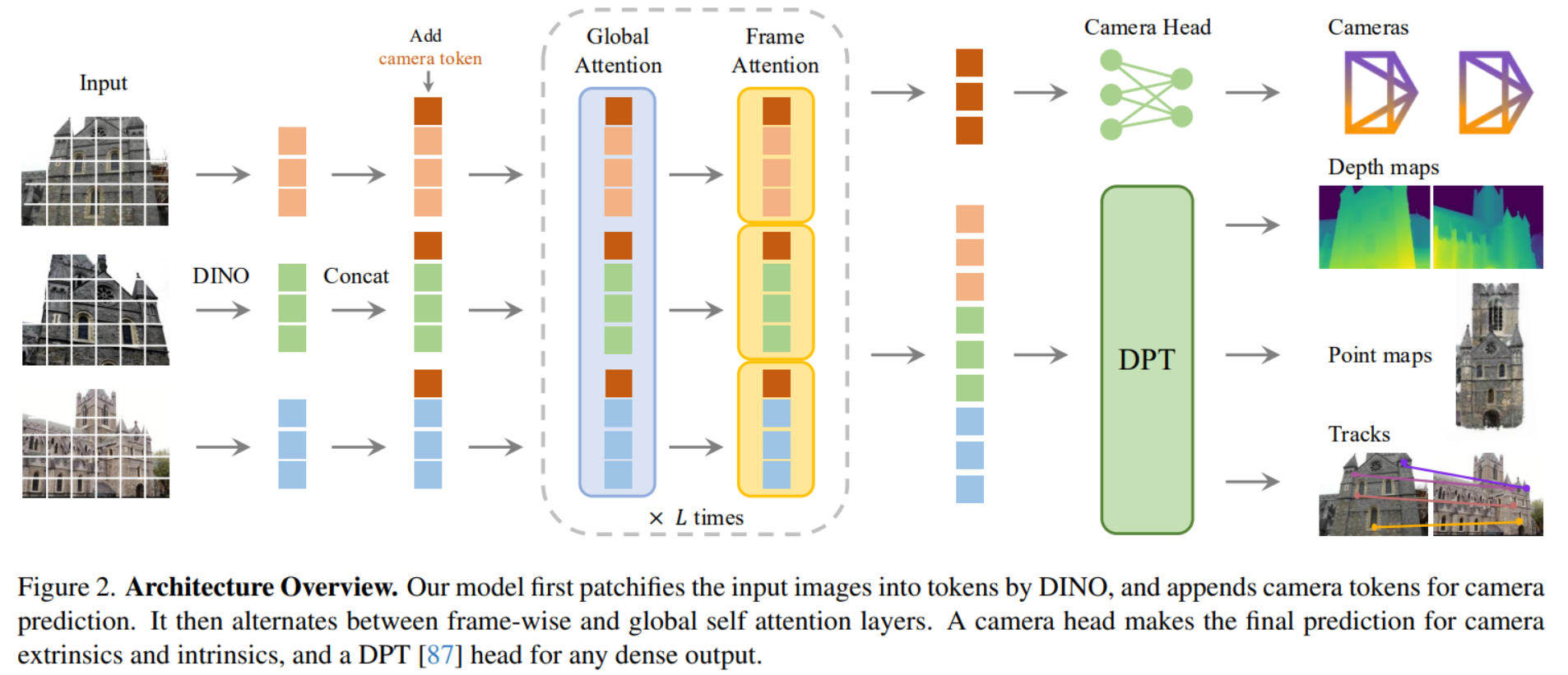
입력 이미지를 패치 단위로 나눔(DINO) -> camera tokens을 추가 -> 프레임 단위(frame-wise)와 전역(global) 자기 주의(self-attention) 레이어를 번갈아 적용-> camera head는 카메라의 extrinsics and intrinsics를 예측 -> DPT( Dense Prediction Transformer ) 헤드 모든 dense 출력 생성
- Frame-wise self-attention
- 각 이미지 안에서만 토큰끼리 정보 교환
- Global self-attention
- 모든 이미지의 토큰이 서로 정보 교환
Global self-attention이게 cross attention이 아닌 이유: a에 b가 맞추는게 아니라 여러 이미지 토큰을 모아서 한 그룹으로 취급하는 Self-Attention일 뿐이고 Query/Key/Value가 “서로 다른 그룹에서 나오는 구조”가 아님. 묻고 답하는게 정해져있는게 아님.
DINO: 이미지 특징 추출 딥러닝 모델(ViT)
이미지 -> patch -> token -> self-attention(정보교환) -> feature vector
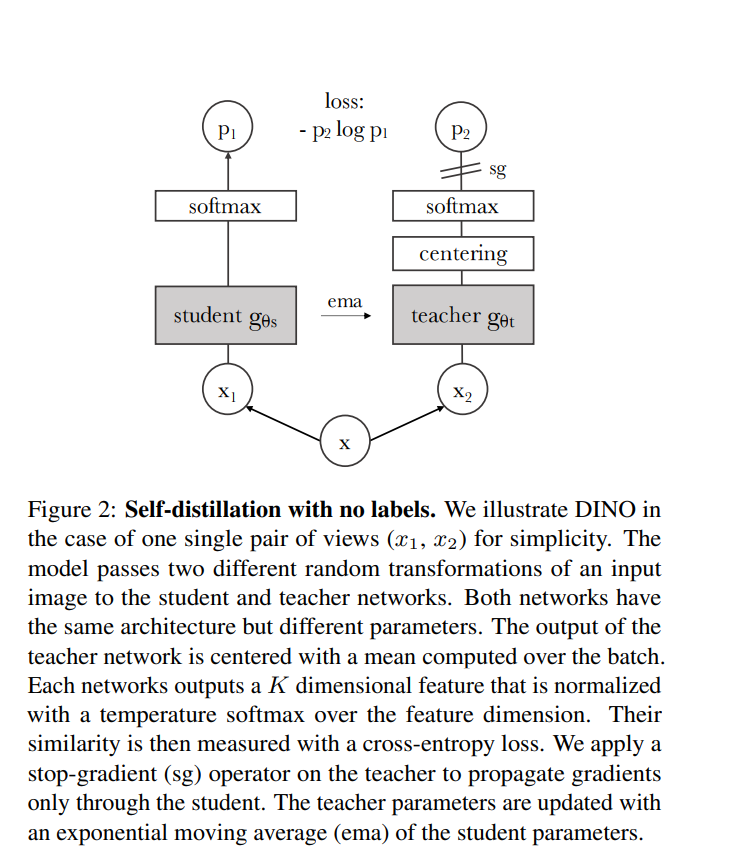
DINO의 pre-trained backbone을 특징 추출기로 차용했을 뿐, KD 방식으로 학습 x.
3.2. Feature Backbone

이미지를 DINO로 패치 벡터로 바꾼 다음, 프레임 내부와 전역 어텐션을 번갈아 돌리는 큰 트랜스포머
3.3. Prediction heads
1. 각 이미지를 DINO로 패치화해서 토큰 벡터 얻음 ( t_I^i )
2. 특별 토큰을 추가
카메라 토큰 (1개), 레지스터 토큰 (4개)
=> [ 이미지 토큰들 ] + [ 카메라 토큰 ] + [ 4개의 레지스터 토큰 ]
- Frame-wise Attention: 각 이미지 안에서 정보 교환
- Global Attention: 모든 이미지끼리 정보 교환
이 과정을 여러 번 반복해서 각 토큰이 점점 더 똑똑
결론적 출력 ->
- t̂_I^i: 이미지 토큰 → 깊이 맵, 포인트 맵, 트랙 예측용
- t̂_g^i: 카메라 토큰 → 카메라 파라미터 예측용
- t̂_R^i: 레지스터 토큰 → 학습 중 보조 역할
t̂_R^i는 그냥 중간 계산을 돕고 학습하는 힌트 역할
최종 예측은 t̂_I^i와 t̂_g^i만 사용
4. Experiments
4.1. Camera Pose Estimation
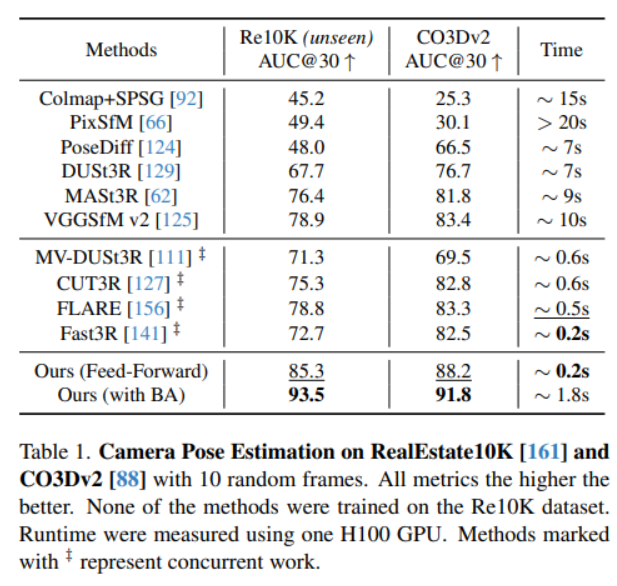
데이터셋 : CO3Dv2 [88] 및 RealEstate10K [161] 데이터셋
장면(scene): 무작위로 10장의 이미지를 선택
평가지표: AUC@30은 RRA( 회전 각도 오차)와 RTA( 평행이동 각도 오차)를 결합한 지표
학습방법: train Co3Dv2 val Co3Dv2이랑 train Co3Dv2 val RealEstate10
Feed-Forward: 한번에, BA (Bundle Adjustment): Feed-Forward 예측 결과를 추가로 최적화
- Dense MVS (Multi-View Stereo) Estimation 성능 비교

데이터: DTU Dataset (GT o)

데이터셋: ETH3D
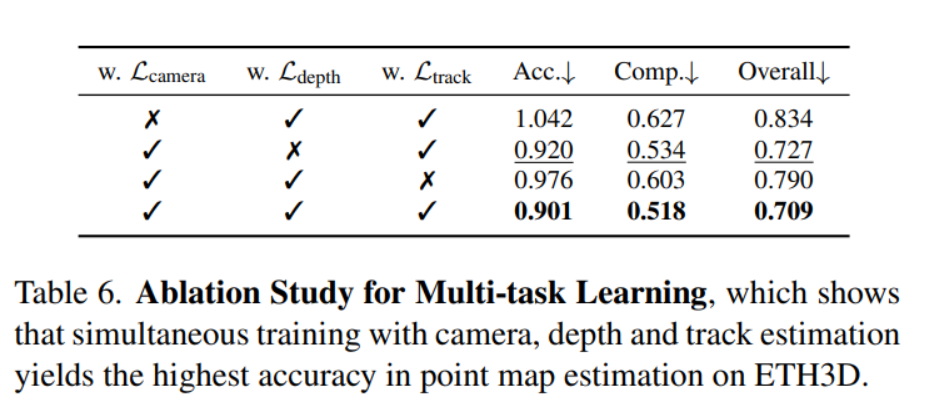
Point, Depth + Cam 필요에 따라 선택해서 사용가능
Two-View Matching 성능 비교

두 장의 이미지에서 동일한 점들을 얼마나 잘 찾아내는지 성능 평가
데이터: ScanNet-1500 Dataset

View Synthesis (NVS, Novel View Synthesis) 성능 평가
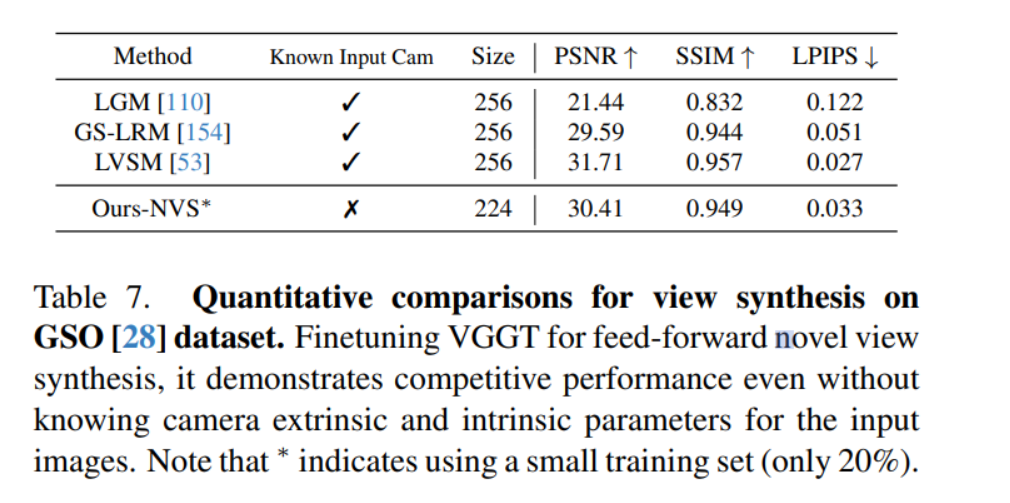
VGGT는 카메라 파라미터 없이도 높은 품질의 새로운 시점 이미지를 합성할 수 있다.

40..?ㅎㅎ A100써볼날이 있을까 내가
6. 결론
Visual Geometry Grounded Transformer(VGGT)
SOTA달성