2025. 7. 18. 20:48ㆍPRO
CVPR2023
ip2p만약 editing 한다면 그대로 사용하는 경우도 많으니 한 번 읽어보는 것도 좋을 듯 하다.
Abstract
GPT-3, Stable Diffusion을 이용하여 대규모 이미지 편집 예제 데이터셋을 생성.
이 생성된 예제 데이터로 InstructPix2Pix 학습하며 실제 이미지와 사람이 쓴 지시문에도 적용 가능하다.
노벨티: 별도의 fine-tuning이나 inversion 없이 forward pass로 editing 수행 가능(몇 초 내에)
1. Introduction
사람이 작성한 지시문을 따라 이미지 편집을 수행하도록 생성 모델을 학습시키는 방법을 제안
대규모 학습 데이터를 확보하는 것이 어렵기 때문에 GPT-3와 Stable Diffusion 사용해서 학습 데이터를 생성한다.
이 데이터로 diffusion-based 이미지 생성 모델을 학습.
이 모델은 입력 이미지와 해당 이미지에 적용할 편집 지시문을 입력받아 편집된 결과 이미지를 직접 생성
제로샷(zero-shot) 달성. 직관적인 이미지 편집을 가능.
2. Prior work
Composing large pretrained models
우리는 GPT-3와 Stable Diffusion 사용해서 멀티모달 학습 데이터를 생성하는 데 초점 둠
Diffusion-based generative models
다양한 곳에서 많이 쓰고있다.(이미지 생성, 영상, 오디오, 텍스트 등)
Generative models for image editing
기존 편집은 style transfer, image-to-image translation 등 단일 편집 함.
또는 CLIP 유사도 목표 함수를 최대화하는 additive image layer를 최적화하여 편집을 수행.
우리는 이러한 기법인 Text2Live 와 비교.
text-to-image diffusion models은 대부분의 경우 유사한 텍스트 프롬프트라도 전혀 다른 이미지를 생성하기 때문에 신뢰하기 어렵
이를 해결하기 위해 Hertz et al.는 Prompt-to-Prompt라는 기법을 제안
이 방법은 유사한 텍스트 프롬프트로부터 생성된 이미지들을 유사하게 유지하면서, localized edit 가능. -> 훈련 데이터 생성 과정에서 사용
이미지를 편집하기 위해서는 SDEdit 이 사용. 입력 이미지에 노이즈를 추가하고 그 후 새로운 텍스트 프롬프트로 디노이징을 수행.
SDEdit을 baseline으로 사용
Learning to follow instructions
기존 방법들은 입력/출력 이미지의 설명, 캡션, 또는 텍스트 라벨을 활용한 반면
우리 방법은 모델이 어떤 작업을 수행해야 하는지를 지시하는 '명령어(instruction)' 기반의 편집을 가능.
편집 명령어를 따르는 방식의 주요 장점은 사용자가 자연어로 모델에게 해야 할 작업을 직접적으로 말할 수 있다는 점(현재 gpt 이미지 생성 및 편집처럼.)
Training data generation with generative models
딥러닝 모델은 일반적으로 대규모 학습 데이터를 필요 하지만
supervision을 위한 적절한 형태(예: 특정 모달리티 간의 짝 지어진 데이터) 찾는건 어렵다.
이 논문에서는 language, text-toimage를 통해 학습 데이터를 생성
3. 방법 (Method)
1. 편집 전/후 이미지와 텍스트 지시어가 짝지어진 학습 데이터셋을 생성
2. 생성된 데이터셋을 사용하여 이미지 편집용 diffusion model을 학습
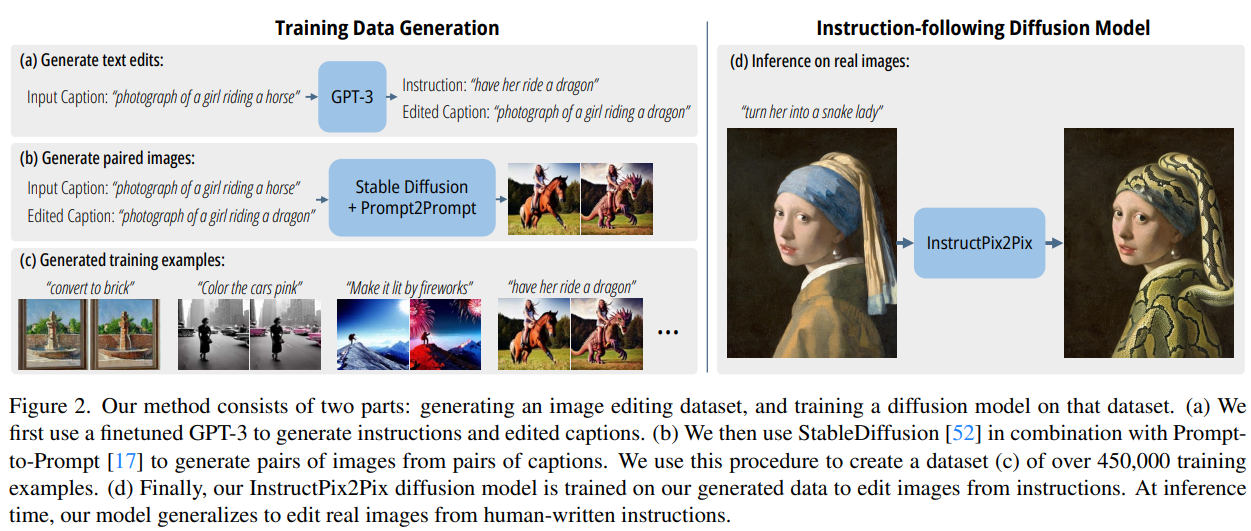
그림 2. 우리의 방법은 두 부분으로 구성됩니다:
- Training Data Generation
- Instruction-following Diffusion Model
(a) 먼저, 파인튜닝된 GPT-3를 사용하여 편집 지시어와 편집 후 캡션을 생성합니다.
(b) 그런 다음, Stable Diffusion과 Prompt-to-Prompt 기법을 결합하여 캡션 쌍으로부터 이미지 쌍을 생성합니다.
(c) 이 절차를 통해 45만 개 이상의 학습 예시로 구성된 데이터셋을 만듭니다.
(d) 마지막으로, InstructPix2Pix 확산 모델을 이 생성된 데이터로 학습시켜, 지시어를 기반으로 이미지를 편집할 수 있게 합니다.
3.1.1 Generating Instructions and Paired Captions
large language model을 image captions으로 받아서 editing instructions과 text captions을 생성.
예시: 입력 캡션이 “말을 타는 소녀의 사진”
편집 지시문: “용을 타게 해줘”
출력 캡션: “용을 타는 소녀의 사진”을 생성
이 논문은 GPT-3를 파인튜닝하여 이 작업을 수행하는 모델을 학습.
이 데이터셋을 만들기 위해 LAION-Aesthetics V2 6.5+, 700개의 입력 캡션을 샘플링, 편집 지시문과 출력 캡션을 작성
이 데이터를 기반으로 우리는 GPT-3 Davinci 모델을 단 한 번의 에폭(epoch) 동안 기본 설정으로 파인튜닝
다만 LAION은 노이즈가 많고 무의미한 캡션도 포함되어 있다는 단점 이를 해결하기 위해
- 데이터 필터링 (3.1.2절),
- Classifier-Free Guidance (3.2.1절)
=> 품질개선

작은 텍스트 데이터셋에 라벨로 GPT-3를 파인튜닝한 뒤, 그 파인튜닝된 모델을 이용해 대규모 텍스트 triplet 데이터셋을 생성
- 입력 캡션 (input caption),
- 편집 지시문 (edit instruction),
- 출력 캡션 (output caption)
3.1.2 Generating Paired Images from Paired Captions
텍스트-투-이미지 모델은 조건이 되는 프롬프트(prompt)에 아주 작은 변화만 주어져도 완전히 다른 이미지를 생성할 수 있으므로, 캡션 쌍을 일관성 있는 이미지 쌍으로 만드는 데 어려움이 있음. => 해결책 Prompt-to-Prompt 사용

Prompt-to-Prompt는 생성된 이미지 간의 유사성을 높이는 데 큰 도움이 되지만, 편집 종류에 따라 이미지 상에서 요구되는 변화량은 달라짐. Prompt-to-Prompt에는 이미지 유사도를 제어할 수 있는 하이퍼파라미터인 p가 존재.
최적의 p 값 찾기 위해 캡션 쌍마다 p 값을 [0.1, 0.9] 구간에서 무작위로 샘플링하여 100개의 이미지 쌍을 생성.
Gal et al. [14]이 제안한 CLIP 기반 방향 유사도(Directional Similarity) 메트릭을 사용해 이 샘플들을 필터링.
3.2. InstructPix2Pix
Latent Diffusion【52】은 사전학습된 VAE의 latent space에서 작업함으로써
모델의 효율성과 품질을 개선.
쉽게 설명하면 기존 SD는 Text->image
이 논문은 image+지시문-> editing된 image
따라서 첨부터 학습 안해도 되고 일부만 파인튜닝해서 사용가능.

S_I: 입력이미지와 유사성
S_T: 편집 지시문과 일치도
3.2.1 Classifier-free Guidance for Two Conditionings
지시문, 원본 이미지를 얼마나 다른지 결정하기 위해 그림4.
훈련할 떄 일부러 이미지조건 5% 제거, 텍스트 조건 5%제거, 둘 다 5%제거 해서 학습.
4. Results
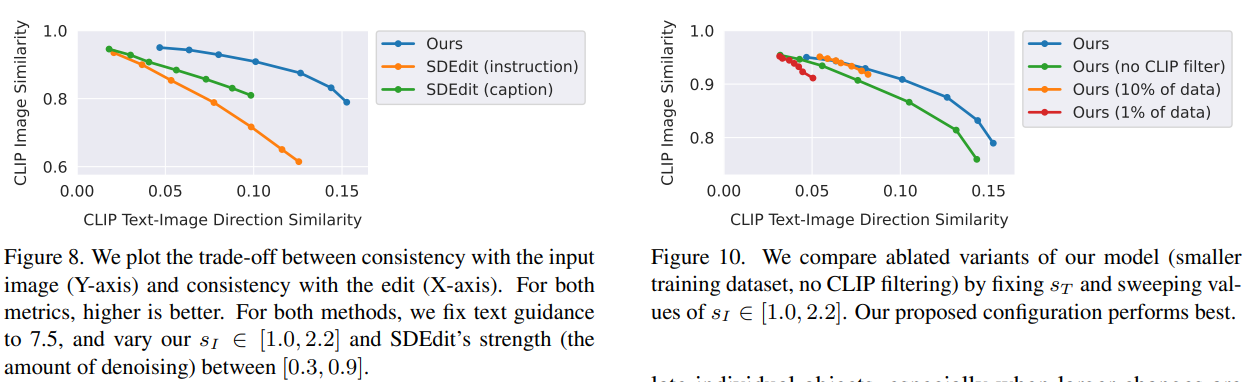
SDEdit , Text2Live랑 정성적으로 비교.
SDEdit과의 정량적 비교