2025. 7. 10. 16:16ㆍPRO

CVPR 2025에 발표된 내용이네. 한국인이라서 눈에 띄었고 개인적으로 Diffusion + 3DGS + 3D Editing에 관심이 생겨서 나름 안질리고 읽음. 근데 Diffusion에 대한 기본 지식 없음 이슈 + 걍 뭐지,,? 싶었음.
근데 막상 읽으면 또 괜춘하드라.(한 10번 읽으면..?ㅎ)
+) 고마운 점은 이거 읽고 발표자료 만들었는데 바로 다음날 KCCV 발표 있는거 확인. 갈 이유가 생겼음 후후.


헤헤 뭐 사담은 요정도 만약 간다면 간 썰 풀겠음 근데 전 석사따리라서 못갈 가능성 다수
저자가 한국인이라서 일단 저자 정보부터.


최근에 (2025 CVPR) 나왔는데 인용 1회인거 실화?
그동안 했던 논문 보니 3D, 딥러닝(생성모델) 쪽 하는 분인듯.
근데 이분 연구실에서 CVPR 2025 2명 보냄.
Abstract
기존 문제: 3DGS는 3D Editing 과정에서 과도한 원본유지를 하여 비효율적으로 최적화한다.
=> 3DGS는 원래 이미지와 유사하게 3D로 렌더링 하기 때문에 당연한 말. 하지만 Editing 시 이는 단점.
따라서, EditSplat를 제시한다.
Multi-view Fusion Guidance(MFG) + Attention-Guided Trimming(AGT) = EditSplat
MFG → 시점 일관
AGT → 3D Gaussian들을 선택적으로 제거(prune) 및 최적화

텍스트 지시만으로 pre-trained 3DGS를 고품질로 Editing가능.
1. Introduction
아니 근데 Introduction이 한페이지 이상임. 말이됨? 왤케 Introduction 길지.,.?
기존 관련 논문들은 multi-view 일관성이 없는 문제. (뷰마다 다르게 )
이를 해결하려고 했지만 역부족(디퓨전 모델 자체를 훈련->높은비용)
기존 방법들은 여전히 multi-view 불일치를 보이며 noisy gradient가 최적화를 방해하고 Editing 효과가 거의 없거나 블러가 포함된 부적절한 출력(suboptimal outputs)을 생성

pre-trained 3DGS는 Editing 시 비효율성이 발생하는데 이는 학습된 Gaussian들이 Geometry, 세부 정보를 과도하게
유지하기 때문에 중복된 Gaussian들을 관리하여 최적화를 더 효과적으로 수행할 필요성 강조

MFG: Multi-view Fusion Guidance
multi-view inconsistency 문제와 pre-trained Gaussian의 최적화 문제를 모두 해결.
multi-view 이미지를 같이 가이드로 줌으로서 editing이 “텍스트에 맞으면서도 multi-view consistency ”을 유지.
원본 이미지도 보조 가이드로 같이 주면서 editing과 원본의 균형을 맞춤.
EditSplat은 multi-view에서 동일하게 보이도록 이미지들을 depth map으로 합치고, 텍스트와 원본 정보를 참고해 빠르고 일관되게 3D 장면을 editing.
AGT: Attention-Guided Trimming
Gaussian에 attention weight를 부여.
높은 attention weight를 가진 Gaussian들은 의미적으로 중요한 영역.
editing 전에 높은 attention weight를 가진 pre-trained Gaussian 중 적절한 비율을 제거(prune)함.
=> 빠르고 정확하게 editing 가능
2. Related Work
1. 2D Image Editing
EditSplat은 *IP2P를 Initial 2D Edited Images 활용.
Classifier-free guidance를 통한 이미지 가이드 기능을 활용하여 multi-view 정보를 디퓨전 과정에 효과적으로 통합. 최종적으로 multi-view 일관성이 유지되는 Editing을 수행해 3D Editing 성능을 향상
2. Text-driven 3D Scene Editing
EditSplat은 multi-view 일관성을 위해 Multi-view Fusion Guidance(MFG)를 도입. pre-trained된 3DGS가 가진 비효율성 문제를 pruning 함으로써 해결하고(AGT) densification와 최적화
효율을 동시에 개선한 것은 본 연구가 최초
*IP2P: 명령어를 받아서, 원본 이미지를 원하는 모습으로 바꿈
3. Method
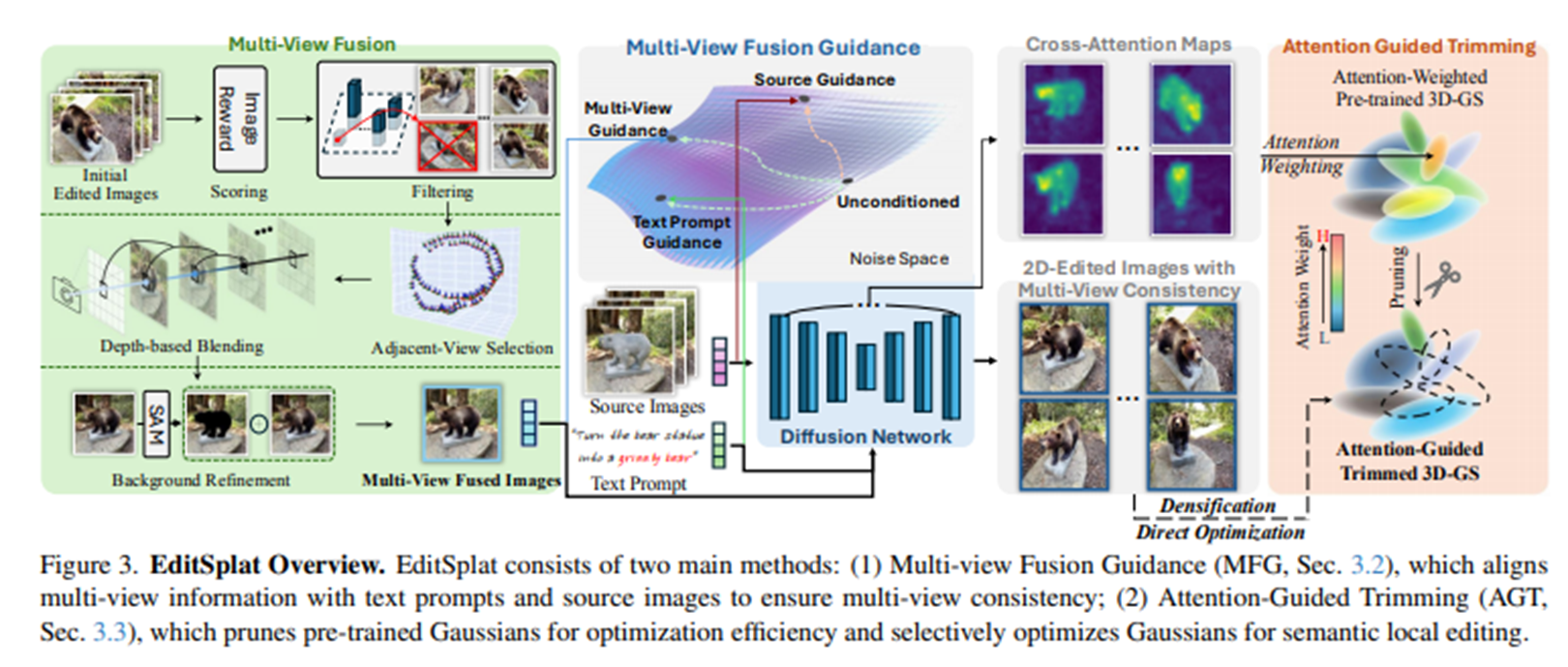
Multi-View Fusion -> Multi-View Fusion Guidance (MFG) -> Attention-Guided Trimming (AGT)
한방에 이해하기 포기. 나눠서 봤음.
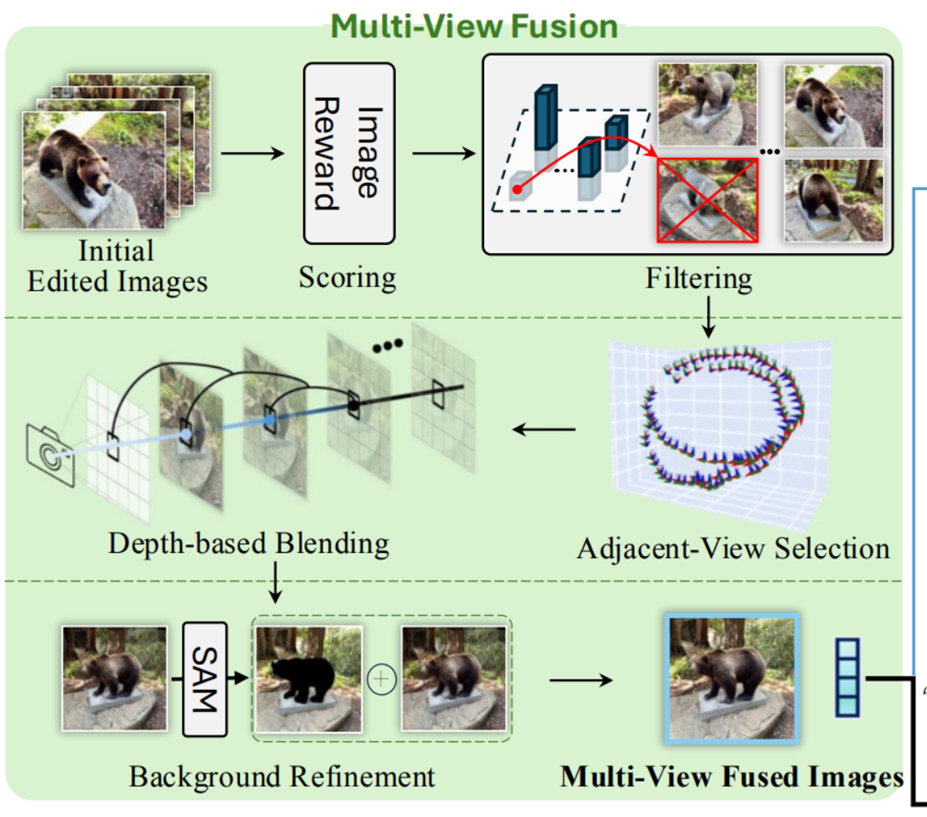
1. Initial Edited Images: InstructPix2Pix가 생성한 편집 결과 이미지
2. Scoring: 각 이미지 품질을 평가해서 점수
3. Filtering: 점수가 낮은 이미지는 버리고 높은 것만 남김(threshold가 몇인지는 안나옴)
4. Adjacent-View Selection: pre-trained 3DGS의 depth map을 사용. 남은 이미지를 중심으로 카메라 뷰포인트 가장 가까운
카메라 pose를 가진 이미지들을 선택
5. Depth-based Blending: 각 시점의 깊이 정보를 기반으로 이미지들을 Blending.
6. Background Refinement: SAM같은 segmentation으로 배경을 구분해 경계부분 더 깨끗하게 만듦.
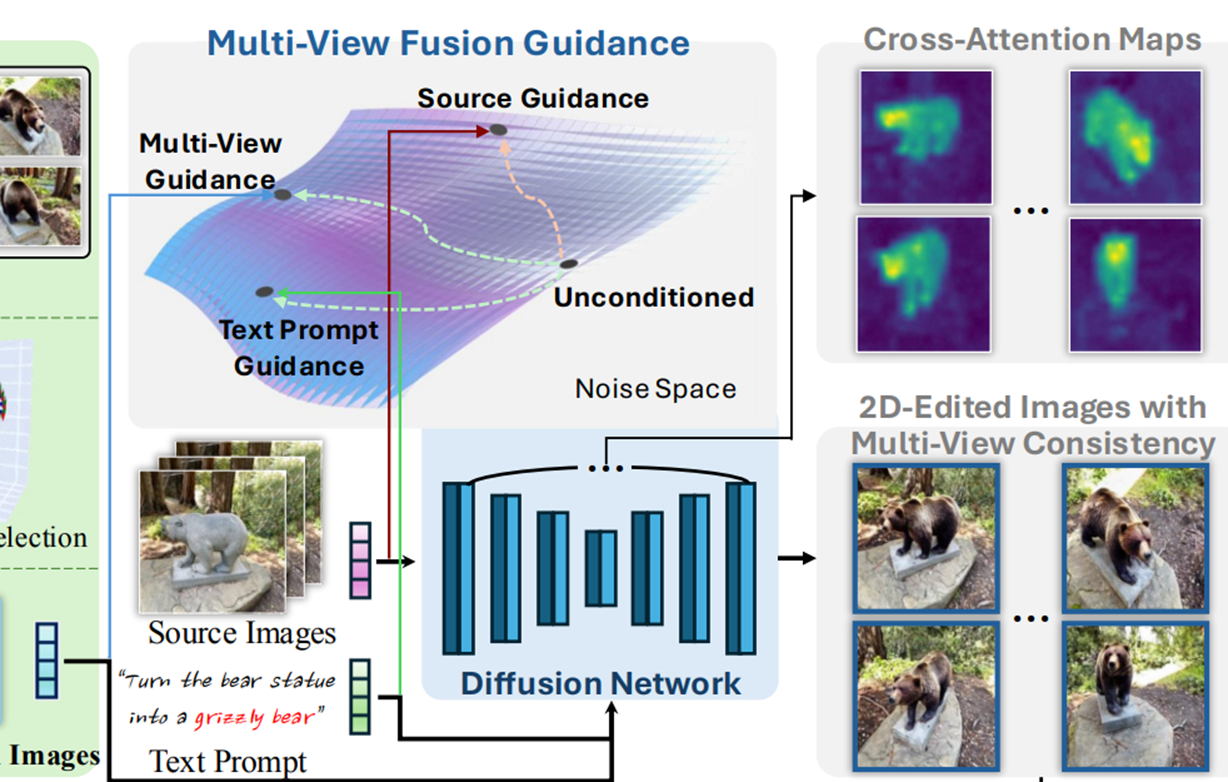
가이드를 동시에 활용: Source Images, Text Prompt, Multi-View Fused Images
결과:2D-Edited Images with Multi-View Consistency 다시 여러 시점에서 일관되게 편집된 이미지 생성!



저 Classifier-free Guidance는 기존에도 많이 쓰는건가봄


3DGS기반 TEXT to 3D 편집한 다른 모델들과 본인 모델을 비교
4. Experiments: Implementation Details
<MFG 유무 실험>

w/o MFG: MFG 사용 안 했을 경우. 뷰마다 일관성 떨어짐
Top: 2D-Edited 결과
Low: Top 이미지들을 기반으로 편집된 3DGS로부터 렌더링한 결과(더 일관성 있음.)
< Hyperparameters >

MFG의 guidance scale을 sT=7.5, sM=1.0, sS=0.5로 설정(이전 baseline과 동일)
pruning 비율 k = 0.15: Gaussian 중 15%를 제거(prune)한다
sT: Text guidance scale
sM: Multi-view guidance scale
sS: Source image guidance scale
[ 정량적 비교 ]

5. Conclusion
이 프레임워크는 Multi-view Fusion Guidance(MFG)와 Attention-Guided Trimming(AGT)로 구성됩니다.
MFG는 핵심적인 멀티뷰 정보를 디퓨전 과정에 통합함으로써 서로 다른 시점에서 일관되고 정밀한 편집을 보장
AGT는 사전 학습된 Gaussian을 Pruning하고 관련된 것들만 선택적으로 최적화하여 최적화 효율을 높이고 의미적으로 풍부하고 정밀한 편집을 가능
SOTA 달성 및 텍스트 기반 3D 장면 편집의 새로운 기준을 제시
Limitations
EditSplat은 2D 디퓨전 모델의 품질과 3DGS [21]로 렌더링된 depth map에 의존
현재의 2D 디퓨전 모델은 복잡하거나 애매한 프롬프트를 처리하는 데 어려움
3DGS의 렌더링 및 depth map 품질도 아직 발전 중이어서 MFG의 projection 과정에 영향을 줄 수 있다.
소감
'PRO' 카테고리의 다른 글
| [논문 리뷰] InstructPix2Pix: Learning to Follow Image Editing Instructions (3) | 2025.07.18 |
|---|---|
| [논문리뷰] Gaussian Grouping: Segment and Edit Anything in 3D Scenes (5) | 2025.07.02 |
| [논문리뷰] VGGT: Visual Geometry Grounded Transformer (0) | 2025.07.01 |